1. JPA 소개
객체 지향 개발을 하고 싶은데, 왜 SQL만 치고 있을까?
우리가 개발을 할 때 사용하는 언어는 보통 Java 같은 객체 지향 언어입니다. (Scala, C# 등등이 있져)
클래스 만들고, 필드 만들고, 메서드 만들고… 객체들끼리 서로 관계도 맺고 상속도 하면서 자연스럽게 설계하죠.
그런데 데이터를 저장할 땐 어쩔 수 없이 관계형 데이터베이스(RDB)를 사용하게 됩니다.
* 물론 데이터 저장하는 법은 NoSQL, File등 다양합니다 (= 객체를 영구 보관하는 저장소로 생각) 현실적인 대안으로 RDB만 언급하겠어요
그리고 여기에 데이터를 넣고 꺼내려면… SQL을 써야 하죠.
SELECT * FROM member WHERE id = 1;
익숙한 문장이긴 한데, 여기서 의문이 하나 생깁니다.
"나는 객체 지향 언어로 개발하고 있는데, 왜 매일 SQL만 치고 있지?"
객체와 RDB, 서로 말이 안 통해요
문제는 객체와 관계형 데이터베이스는 사고방식이 완전히 다르기 때문이에요.
예를 들어서…
✅ 객체는 연관된 객체를 '참조'해요
member.getTeam()
❌ RDB는 외래 키(FK)로 관계를 만들어요
SELECT * FROM member m JOIN team t ON m.team_id = t.id
객체에서는 그냥 getTeam() 하면 되는데, SQL에선 JOIN을 써야 하고, foreign key 신경 써야 하고, 심지어 양방향 관계라도 다 직접 처리해야 합니다.
즉, 객체와 RDB의 패러다임이 불일치 합니다.
객체를 RDB에 저장하려면 객체를 그에 맞춰 SQL(INSERT)로 변환하고, SQL을 통해 RDB와 통신해야 해요. RDB에서 객체를 조회할 때도 SQL(SELECT)로 조회한 다음 객체로 변환해야 합니다
이 역할을 하는 게 개발자로, 객체와 RDB 사이에서 일하는(?) SQL 매퍼라고 봐도 된다고 해요
객체다운 코드를 쓰고 싶지만…
객체답게 모델링을 하고 싶어도 현실은 녹록치 않습니다.
- 상속 관계? → 테이블 나눠서 JOIN해야 해요
- 객체 그래프 탐색? → 쿼리에 JOIN을 다 써야 가능해요
- 참조 기반 설계? → SQL로 처리하려면 너무 복잡해요
- 성능 고려? → 결국 쿼리를 직접 짜야 해요
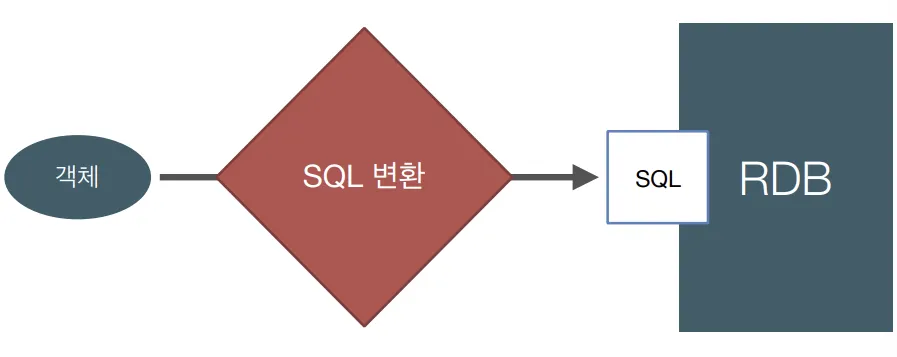
그러다 보면 결국은 이렇게 되죠.
"객체지향 설계 따윈 집어치우고, 테이블에 맞춰 코드 짜자..."
하지만 이건 너무 아쉽지 않나요? 객체지향 언어로 개발하면서 객체지향답게 코드를 못 짜는 상황이니까요..
오잉? 이렇게만 이야기하면 왜 아쉬운지 잘 모르겠어요ㅠ!
그렇다면 딱 4가지 관점에서 봐봅시다~
1. 상속
객체에는 상속 관계가 존재하지만, DB 테이블엔 객체에서 생각할 수 있는 상속 관계는 없어요.
그래서 보통 RDB에선 오른쪽 그림처럼 슈퍼타입(부모)과 서브타입(자식)으로 나눠 테이블을 구성해요.
이 방식을 사용하면 저장공간에 데이터를 분리해서 저장해놨다가 필요할 때 조인해서 가져오고 또 분리해서 저장해둬요
- 예를 들어 Book 데이터를 저장할 때는
Book 객체를 분해한 뒤 ITEM과 BOOK 테이블에 INSERT 문을 각각 날려야 해요.
조회할 때도 마찬가지로, ITEM과 BOOK 테이블에 대한 조인 SQL을 작성하고 Book 객체를 생성해 반환해야해요... - 뭔소리야 싶죠? 글로 이렇게 설명해둬도 이해하기 어려운데 코드로는 더 복잡하기 때문에 DB에 저장할 객체엔 되도록 상속 관계를 쓰지 않고 설계해요.

상속 관계에 관련해서 이 책의 저자는 이렇게 말씀해요
자바 컬렉션에 저장하는 방식은 한 줄이면 된다. 조회도 마찬가지다. 객체 세상은 간단하지만 DB는 간단하지 않다.
저장: list.add(book);
조회: Item item = list.get(bookId);
위의 내용에서 DB로 쿼리를 짜면 이런식이겠죠?
-- 부모 테이블: ITEM
INSERT INTO ITEM (ITEM_ID, NAME, PRICE)
VALUES (1, 'Clean Code', 20000);
-- 자식 테이블: BOOK
INSERT INTO BOOK (ITEM_ID, AUTHOR, ISBN)
VALUES (1, 'Robert C. Martin', '9780132350884');
SELECT * FROM ITEM i JOIN BOOK b ON i.ITEM_ID = b.ITEM_ID WHERE i.ITEM_ID = 1;
엥? 이렇게 쿼리 날리는데 머가 복잡해여 ㅡㅡ;; 이렇게 느낄 수 있지만..
java로 dto를 설계해서 controller로 만들고 service에서 이를 분리해서 sql 쿼리를 날리게끔 만드는걸 하다보면 귀찮아요
2. 연관관계
객체는 참조를 사용해 연관 관계를 맺어요. 그에 비해 테이블은 외래 키로 테이블을 조인해 연관 관계를 맺습니다
- 참조: member.getTeam()
- 외래 키: JOIN ON M.TEAM_ID = T.TEAM_ID

보통은 객체를 테이블에 맞춰 모델링을 하기 때문에 Member에 Team team라는 객체를 넣는것보단 Long teamId 필드를 넣어 설계하게 됩니다. 그래야 INSERT나 JOIN을 할 때 편해요
- 물론 객체답게 모델링을 진행하려면 Member에 Team team 필드를 넣어 설계해도 됩니다.
대신 SQL 관점에서 로직이 굉장히 까다로워진다는 문제가 생겨요. 객체로 JOIN 하려면 참조로 접근해 필드 값을 받아와야 합니다 - 예를 들어 객체 모델링을 통해 회원을 조회하려면 아래와 같이 복잡한 로직을 구현해야 해요
// 회원 조회
public Member find(String memberId) {
Member member = new Member();
...
Team team = new Team();
...
member.setTeam(team);
return member;
}
이것도 자바 컬렉션에선 한 줄이면 가능하다.
저장: list.add(member);
조회: Member member = list.get(memberId);
3. 탐색 범위
객체는 자유롭게 객체 그래프를 탐색할 수 있어야 해요. 참조에 참조를 통해 Member에서 Category까지도 접근할 수 있어요.
그러나 테이블은 처음 실행하는 SQL에 따라 탐색 범위가 결정됩니다. 예를 들어 아래 SQL처럼 MEMBER 테이블과 TEAM 테이블을 JOIN 했다면 member.getTeam()은 가능하지만, ORDER 테이블은 JOIN 하지 않았기 때문에 member.getOrder()은 null로 떠요
SELECT M.*, T.*
FROM MEMBER M
WHERE TEAM T ON M.TEAM_ID = T.TEAM_ID;
따라서 엔티티에 대한 신뢰 문제가 생기게 됩니다. 예를 들어 아래 process() 메서드에서 memberDAO에서 find() 메서드로 찾아온 Member 객체의 탐색 범위가 어디까지인지 확인해야만 member 객체에서 어디까지 값을 가져올 수 있는지 알 수 있다.
- 계층을 분할한다는 건 다른 계층에 대한 신뢰를 바탕으로 진행된다. 내가 데이터를 주면 원하는 데이터가 반환된다는 신뢰성이 중요하다. 그런 의미에서 엔티티를 신뢰할 수 없다는 건 진정한 의미의 계층 분할이 어려워진다는 것을 뜻한다.
- 그럼 모든 객체를 미리 로딩해 두면 되지 않냐고 생각할 수 있지만... 당연히 SQL 길이나 쿼리 성능에 문제가 생긴다.
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam(); // 가능할까?
member.getOrder().getDelivery(); // 가능할까?
}
- 위와 같은 선택을 하게 된다면 성능이 느려진다~
3. 탐색 범위
객체는 연결된 만큼 자유롭게 탐색할 수 있어요.
예를 들어, Member 객체가 있고 거기에 이렇게 연관된 객체가 붙어 있다고 해볼게요
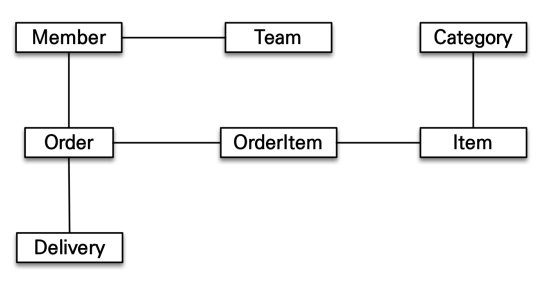
Member → Team
→ Order → Delivery
이걸 객체로 표현하면 이런 식이겠죠:
member.getTeam(); // 팀 정보
member.getOrder().getDelivery(); // 주문 → 배송 정보
이건 객체라서 가능한 거예요.
내가 member 하나만 있으면, 그 참조를 타고 계속 "그래프 탐색"을 할 수 있어요. (연결이 되어있으니까)
하지만 SQL은 내가 JOIN한 테이블까지만 데이터를 가져올 수 있어요.
예를 들어 이런 SQL을 실행했다고 해봐요
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID;
이 쿼리는 MEMBER + TEAM 정보까지만 가져옵니다. 즉, 이 결과로 만든 Member 객체는
member.getTeam(); // 가능 ✅
member.getOrder(); // null ❌
ORDER에 대한 JOIN이 없기 때문에 getOrder()는 null이에요. 당연히 getOrder().getDelivery()는 NPE(null point exception)가 터지겠죠.
우리가 개발할 때는 보통 이런 식으로 코드를 나눕니다:
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam(); // 가능할까?
member.getOrder().getDelivery(); // 가능할까?
}
// 심장 떨리죠? 재밌죠?근데 위 코드에서 memberDAO.find()가 어디까지 JOIN 했는지 process() 입장에서는 알 수가 없어요.
그냥 Member를 줬을 뿐인데, 그 내부에 뭐가 채워져 있는지는 모르는 거예요.
이 때문에 엔티티의 신뢰가 무너져요
DAO가 Member를 줬다고 해도, 그 안에 뭐가 있는지 모르기 때문에 getTeam(), getOrder() 같은 메서드를 마음 놓고 쓰기가 어려워요.
이 말은 곧, "계층 분리"를 했다고 해도, 그 계층에서 받은 객체를 믿을 수 없다면 진짜 분리가 안 되었다고 보는 입장입니다
그럼 그냥 다 JOIN 때릴까?싶죠? 좋은 질문이에요. 모든 연관된 테이블을 JOIN 해버리면? 성능이 무너집니다
(*책에서는 그럼 모든 객체를 미리 로딩해 두면 되지 않냐는 워딩을 써요)
SQL이 길어지고 불필요한 데이터까지 모두 끌고 오고 테이블이 많아질수록 성능이 급격히 나빠져요
즉, "안전하게 모든 걸 다 가져오자!"는 비용이 너무 큽니다.
4. 데이터 타입 및 식별 방법
객체를 비교할 때 우리는 두 가지 방식을 사용할 수 있어요.
- == → 동일성 비교 (메모리 주소가 같은지 확인)
- .equals() → 동등성 비교 (내용이 같은지 확인)
보통 우리는 "같은 회원"을 비교할 때 .equals()를 쓰지만, JPA나 캐시, 컬렉션에서는 == 비교가 굉장히 중요한 의미를 가집니다.
우리가 SQL을 직접 사용해서 DB에서 회원 정보를 두 번 조회하면,
그때마다 새 자바 객체가 만들어집니다. ( 새로운 인스턴스로 만들어 반환 )
Member m1 = memberRepository.findById(1); // 첫 번째 쿼리
Member m2 = memberRepository.findById(1); // 두 번째 쿼리
System.out.println(m1 == m2); // false ❌
같은 ID를 가진 회원이지만, 두 객체는 서로 다른 메모리 주소를 가지는 완전히 다른 인스턴스예요.
즉, == 비교는 당연히 실패하게 되죠.
자바 컬렉션은 이미 저장해둔 객체를 꺼내오기 때문에, 항상 같은 인스턴스를 반환합니다. 그래서 == 비교도 통과해요.
Map<Long, Member> memberMap = new HashMap<>();
memberMap.put(1L, new Member(1L, "코헤"));
Member m1 = memberMap.get(1L);
Member m2 = memberMap.get(1L);
System.out.println(m1 == m2); // true ✅
JPA는 내부에 1차 캐시(EntityManager의 영속성 컨텍스트)를 가지고 있어요.
한 번 조회한 엔티티는 이 캐시에 저장되기 때문에, 같은 트랜잭션 내에서 동일 ID로 다시 조회하면 같은 객체를 반환합니다.
Member m1 = em.find(Member.class, 1L);
Member m2 = em.find(Member.class, 1L);
System.out.println(m1 == m2); // true ✅
이건 동일성까지 보장하는 객체 관리 시스템이라는 뜻이고, 그만큼 객체의 신뢰도가 높아진다는 의미예요.
불변성이란?
불변 객체(immutable)는 한 번 만들어진 후 값을 바꿀 수 없는 객체를 말해요.
예를 들어, String, Integer, LocalDate 같은 것들이 있죠. JPA는 가변 객체(mutable)를 관리하는 기술이에요. 엔티티의 값이 변경되면 JPA가 그 변경을 감지해서 DB에 반영합니다.
그래서 엔티티는 보통 불변이 아닙니다. 하지만 최근에는 읽기 전용 값 객체(Value Object)나 DTO 계층에서는 불변 객체를 선호하기도 해요.
* 이 때의 객체가 mutable하면 개발자가 읽기 어려움이 있다.(이펙티브 자바)
불변 객체는 상태 추적이 쉬워지고, 멀티스레드 환경에서도 안전하다는 장점이 있거든요.
- 불변을 선호할 경우 JPA는 고려대상에서 제외되기도 해요
- 객체지향은 객체는 변경이 가능하다고 보는 패러다임이며 객체들이 각자의 상태를 지정할 수 있어요.
모던한 프로그래밍은
상태를 줄여버리면 읽기 편해지므로 불변을 한 뒤 불변이 안되는 부분만 체계적으로 관리하는 방향성이 있다고 해요
2. JPA 시작
ORM과 JPA에 대해 알아봅시다
ORM(Object-Relational Mapping)은 말 그대로 객체와 관계형 데이터베이스를 매핑해주는 기술이에요.
쉽게 말해,
- 객체는 객체답게 (Member, Team, Order)
- DB는 DB답게 (MEMBER, TEAM, ORDER)
설계하되, 중간에서 둘을 이어주는 역할을 ORM이 해줍니다.
개발자는 이제 매번 SQL을 직접 작성하는 대신, 객체를 저장하면 알아서 SQL이 날아가고, DB에서 조회하면 객체로 변환돼 돌아오게 되는 거죠.
자바 진영의 ORM 표준, JPA
JPA(Java Persistence API)는 자바 진영에서 정의한 ORM 기술의 표준 명세예요.
ORM: 개념과 기술
JPA: 자바 진영의 ORM 표준
JPA는 JDBC 위에 올라가요
기본적으로 자바 애플리케이션이 데이터베이스와 통신하려면 JDBC API를 써야 해요. 하지만 JDBC는 아주 저수준의 API입니다.
JDBC API만 쓸 때는 아래와 같은 문제가 있어요
- SQL 문자열 직접 작성
- DB 커넥션 직접 관리
- ResultSet → 객체 수동 변환
- 반복되는 보일러플레이트 코드
- 보일러플레이트 코드란? : 최소한의 변경으로 여러 곳에서 반복적으로 사용되는 코드라고 해요
JPA는 이 JDBC 위에서 동작하면서 우리가 직접 SQL을 짜지 않아도 되도록 추상화를 제공해줍니다.
즉,
em.persist(member); // 저장
em.find(Member.class, id); // 조회
→ 내부에선 JDBC 써서 SQL 날리고 처리 다 해줍니다

SQL을 직접 안 써도 되니까 개발이 훨씬 편해지는 건 사실이지만,
그만큼 우리가 놓치는 것도 생깁니다.
대표적인 게 바로… N+1 문제에요
N+1 문제란?
“이건 뭐야, 쿼리가 왜 이렇게 많이 날아가?? 😨”
JPA를 처음 써본 사람이라면
처음 맞닥뜨리는 벽이 바로 이 N+1 문제입니다.
하나의 쿼리를 날렸는데,
관련된 엔티티 개수만큼 추가 쿼리(N개)가 더 실행되는 상황
예를 들어…
List<Member> members = memberRepository.findAll();
for (Member member : members) {
System.out.println(member.getTeam().getName());
}
이 코드가 문제가 되는 이유는, findAll()에서는 Member만 조회했기 때문에 getTeam()을 호출할 때마다 추가로 Team을 조회하는 쿼리가 발생하는 거예요.
즉
- 1개의 SELECT * FROM MEMBER
- 그리고 각 멤버마다 N개의 SELECT * FROM TEAM WHERE id = ?
➡ 총 N+1개의 쿼리
JPA는 기본적으로 연관 관계는 지연 로딩(Lazy Loading)을 사용합니다.
즉, 실제로 그 데이터가 필요해질 때까지는 DB에서 가져오지 않고 "프록시 객체"만 둡니다.
그래서 getTeam() 같은 걸 호출할 때 그제서야 쿼리를 날리는 거예요.
이걸 모르면 생기는 문제
- 서비스 로직에서 순식간에 수십, 수백 개의 쿼리가 실행될 수 있어요
- 성능 저하로 이어지고, 디버깅도 어렵습니다
- "쿼리 왜 이렇게 많이 날아가죠?" 하는 일이 생김
JPA의 동작 과정
JPA는 겉으로 보기엔 JDBC 템플릿이나 MyBatis 같은 ORM과 비슷해 보일 수 있어요.
하지만 JPA는 훨씬 간단하면서도 객체와 RDB 간의 패러다임 불일치 문제를 해결해 준다는 점에서 강력한 차별점을 갖고 있습니다.
📌 자바 컬렉션처럼 save() 하고 get() 하듯 DB와 통신할 수 있다는 게 JPA의 가장 큰 장점이에요!
저장 과정
em.persist()를 호출하면, JPA는 전달받은 엔티티를 분석해 INSERT SQL을 자동 생성합니다.
이후 내부적으로 JDBC를 사용해 DB에 접근하고, 데이터를 저장합니다.

👉 전체 흐름:
persist() → 엔티티 분석 → SQL 생성 → JDBC 통해 DB에 저장
💡 참고: DAO는 Data Access Object의 약자로, DB 접근 로직을 담당하는 계층이에요.
조회 과정

em.find()를 호출하면, JPA는 SELECT SQL을 자동 생성해 DB에 요청을 보냅니다.
반환된 ResultSet을 분석하고, 해당 데이터를 엔티티 객체로 변환해서 반환합니다.
👉 전체 흐름:
find() → SQL 생성 → JDBC 실행 → ResultSet 매핑 → 엔티티 반환
객체와 RDB의 패러다임 불일치 해결방법
1. JPA와 상속
위에서 엔티티 하나를 저장하려면 테이블 2개에 INSERT SQL을 생성해 날려야 했어요.
JPA를 사용하면 코드 한 줄(persist(), find() 등)만 적으면, 개발자가 직접 하던 나머지 과정을 JPA가 알아서 처리해 줍니다


2. JPA와 연관관계
원래는 외래 키를 사용해 JOIN 하고 연관관계를 맺어야 하지만, JPA를 사용하면 참조를 통해 연관관계를 맺을 수 있어요.

3. JPA와 객체 그래프 탐색
객체 그래프 탐색도 자유롭게 가능하기 때문에 엔티티에 대한 신뢰 문제가 해결돼요. 계층이 분할돼 있더라도 믿고 사용할 수 있어요
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam(); // OK
member.getOrder().getDelivery(); // OK
}
4. JPA와 비교(==)하기
같은 아이디를 가진 회원을 조회한 뒤 두 회원이 같은지 비교할 때도, JPA를 사용하면 동일한 트랜잭션 내에서 조회한 엔티티의 동일성을 보장해요.(1차캐시 덕분에!) 따라서 ==로 비교해도 true가 나오게 됩니다.
- 자바 컬렉션에서 꺼내 비교할 때랑 같다고 보면 됩니다.
성능 최적화 기능 제공
1. 1차 캐시와 동일성(identity) 보장
JPA는 내부적으로 1차 캐시(영속성 컨텍스트)를 사용해요.
이건 같은 트랜잭션 안에서 이미 조회한 엔티티를 메모리에 저장해 두었다가, 같은 ID로 다시 조회할 경우 SQL을 실행하지 않고 캐시에서 꺼내주는 기능이에요.
String memberId = "100";
Member m1 = jpa.find(Member.class, memberId); // SQL 사용
Member m2 = jpa.find(Member.class, memberId); // 1차 캐시에서 꺼내 옴
// 같은 트랜잭션 내에서 같은 엔티티를 2번 이상 조회할 때, SQL을 1번만 실행해도 됨
즉, 같은 트랜잭션 안에서는 같은 객체 인스턴스가 반환돼요.
Repeatable Read와 유사한 동작
DB의 고립 수준(isolation level)은 다음과 같은 단계로 나뉘죠:
- Serializable
- Repeatable Read
- Read Committed ← 대부분의 RDB 기본값
- Read Uncommitted
JPA는 DB가 Read Committed 수준이더라도, 1차 캐시 덕분에 애플리케이션 안에서는 Repeatable Read와 유사한 동작을 해요.
즉, 같은 트랜잭션 내에서 같은 엔티티를 두 번 조회하면 항상 동일한 값을 반환합니다.
2. 트랜잭션을 지원하는 쓰기 지연 (Transactional Write-Behind)
JPA는 SQL을 바로 실행하지 않고, 트랜잭션 커밋 시점까지 모아두었다가 한 번에 실행합니다. 이걸 쓰기 지연(write-behind) 전략이라고 해요.
INSERT의 경우
persist()를 호출해도, 즉시 DB에 INSERT 쿼리가 날아가지 않아요. JPA는 SQL을 모아두었다가 트랜잭션 커밋 시점에 JDBC Batch를 통해 한 번에 보냅니다.
transaction.begin(); // 트랜잭션 시작
em.persist(m1);
em.persist(m2);
em.persist(m3);
// INSERT SQL은 아직 실행되지 않음
transaction.commit(); // 커밋 시점에 모아둔 INSERT SQL 실행
장점: DB와의 커넥션/트래픽 최소화 → 성능 최적화
UPDATE, DELETE의 경우
수정하거나 삭제할 때도 마찬가지로, 트랜잭션 커밋 직전까지 SQL을 실행하지 않아요.
transaction.begin(); // 트랜잭션 시작
changeMember(m1);
deleteMember(m2);
// 이 시점에는 실제로 DB에 UPDATE, DELETE 쿼리가 안 나감
비즈니스_로직_수행(); // 이 동안 row lock 없음
transaction.commit(); // 커밋 시점에 UPDATE, DELETE SQL 실행
장점
- row lock 시간을 최소화 → 다른 트랜잭션과의 충돌 줄임
- 동시에 처리되는 요청이 많을 때 성능 향상
참고: JPA는 기본적으로 낙관적 락(Optimistic Lock) 방식을 따릅니다
- "DB 충돌은 잘 안 날 거야"라고 가정하고,
- 커밋 시점에 문제가 생기면 그때 예외 처리함
* 반댓말은 비관적 락이라고 해요
3. 지연 로딩 (Lazy Loading)
필요할 때까지 로딩을 미루는 방식
Member member = memberDAO.find(memberId); // SELECT * FROM MEMBER
Team team = member.getTeam();
String teamName = team.getName(); // SELECT * FROM TEAM
- member.getTeam()을 호출할 때 실제 쿼리가 실행됨
- 객체를 참조할 때까지 DB 접근을 미룸
- 연관 객체가 많을수록 불필요한 조회를 방지할 수 있음
즉시 로딩(Eager Loading)
처음부터 JOIN으로 연관 객체까지 모두 가져오는 방식
Member member = memberDAO.find(memberId); // SELECT M.*, T.* FROM MEMBER M JOIN TEAM T ...
Team team = member.getTeam();
String teamName = team.getName(); // 추가 쿼리 없음
- 조회 시점에 JOIN 쿼리로 한꺼번에 로딩 성능이 좋을 수도 있지만, 불필요한 데이터까지 가져올 위험도 있음
보통은 기본은 대부분 지연 로딩으로 설정, 필요할 때만 즉시 로딩으로 최적화 (ex. fetch join 사용)
A Short Guide to Hibernate 7
To interact with the database, that is, to execute queries, or to insert, update, or delete data, we need an instance of one of the following objects: a JPA EntityManager, a Hibernate Session, or a Hibernate StatelessSession. The Session interface extends
docs.jboss.org
Hibernate와 JPA(표준 명세)
1) 배경과 역사 한 줄 요약
- 옛날 EJB 엔티티 빈은 쓰기 어렵고 느렸어요 → 실무자들이 만든 오픈소스 Hibernate가 대세가 되었어요
- 그래서 자바 진영이 Hibernate 아이디어를 표준화해 만든 게 JPA(Java Persistence API).
- 지금은 JPA = 표준(인터페이스 집합), Hibernate = 구현체(라이브러리) 로 이해하면 됨.

2) JPA는 “표준”, Hibernate는 “구현체”
- JPA: 표준 명세(인터페이스 모음). 구현은 없음.
- 구현체: Hibernate, EclipseLink, DataNucleus 등.
실무에선 Hibernate가 사실상 표준.
3) 버전 흐름
- JPA 1.0 (JSR 220) (2006): 초기 버전 복합 키나 연관관계 기능이 부족했다.
- JPA 2.0 (JSR 317) (2009): 주요 ORM 기능 + JPA Criteria
- JPA 2.1 (JSR 338) (2013): Stored Procedure, Converter, EntityGraph
- JPA 2.2: 관리하기 싫다고 이클립스가 가져감.. 이후 패키지명 변경
- 이후 Jakarta Persistence로 이관(패키지 변경):
- javax.persistence → jakarta.persistence
- Jakarta Persistence 3.0/3.1/3.2 (현재는 Jakarta 이름으로 계속 업데이트 중)
이름만 바뀐 게 아니라 관리 주체가 Eclipse Foundation로 바뀌고, 패키지가 jakarta.*로 변경됨.
4) Hibernate가 JPA를 구현하는 방식
- JPA의 핵심 API는 EntityManager.
- Hibernate는 JPA 외에 자체 API도 제공:
- Session: Hibernate 고유 인터페이스 (JPA EntityManager와 유사하지만 기능 더 많음)
- StatelessSession: 1차 캐시/스냅샷 없이 가볍게 대량 처리할 때 사용
- 포터빌리티(이식성)를 원하면 JPA API 우선 → 벤더 특화 기능이 필요할 때만 Hibernate API(Session) 선택.
5) 참고 문서
- Hibernate 공식 가이드: (Hibernate 7 Introduction) — 고유 기능/최적화는 여기서 확인 https://docs.jboss.org/hibernate/orm/7.1/introduction/html_single/Hibernate_Introduction.html
A Short Guide to Hibernate 7
To interact with the database, that is, to execute queries, or to insert, update, or delete data, we need an instance of one of the following objects: a JPA EntityManager, a Hibernate Session, or a Hibernate StatelessSession. The Session interface extends
docs.jboss.org

'Spring, SpringBoot, JPA' 카테고리의 다른 글
| 3. 엔티티 매핑 (0) | 2025.08.16 |
|---|---|
| 2. 영속성 관리 (0) | 2025.08.16 |
| Spring Security와 사용자 역할 관리: 오늘의 학습 내용 정리 (0) | 2024.08.27 |
| JWT를 이용한 Spring Security 인증 구현하기 (0) | 2024.08.27 |
| SpringBoot Project 게시판 만들기 2 (1) | 2024.05.24 |
